AI模型评测
找到 18 个相关网站
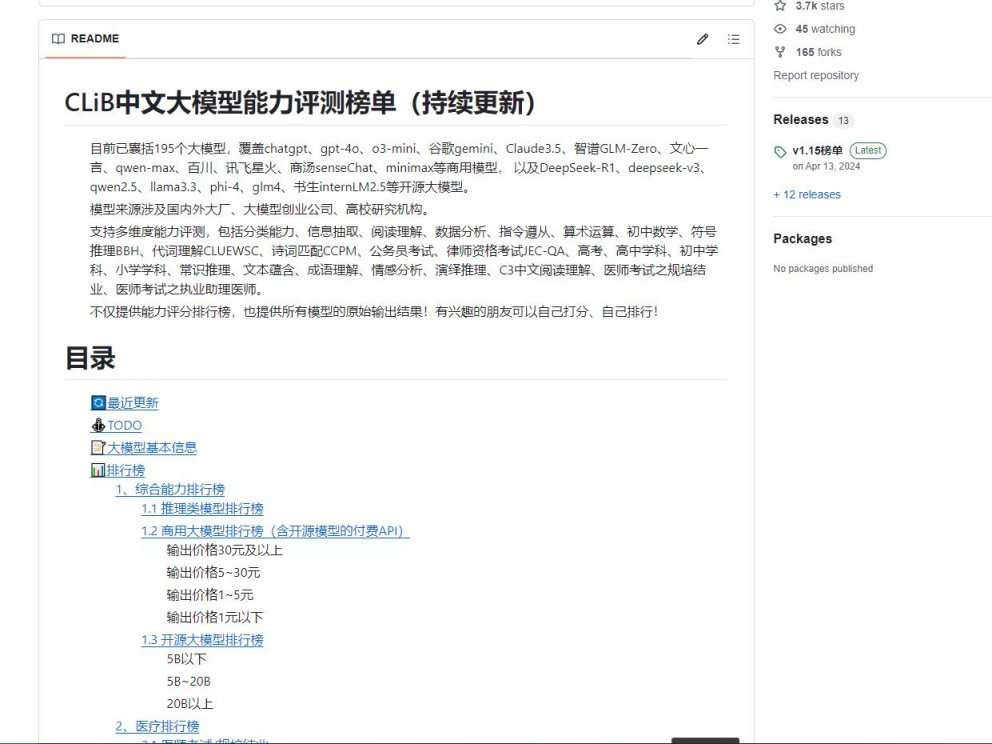
CLiB中文大模型能力评测榜单
是一个关于中文大模型能力评测的榜单仓库,涵盖 195 个商用

FlagEval 致力于提供科学、公正、开放的大模型评测平台,提升模型性能评估的效率与客观性
FlagEval致力于提供科学、公正、开放的大模型评测平台,
LYi 林哥的大模型野榜
让用户出题,安排AI模型回答,由用户选择评判,从而对大模型进

H2O Eval Studio EvalGPT AI 全面评估生成式AI与LLM应用的智能平台
H2O Eval Studio 作为H2O.ai 旗下的一款
FlagEval (天秤)大模型评测
FlagEval (天秤)大模型评测体系及开放平台,旨在建立

superbench 大模型评测榜单
SuperBench是由清华大学基础模型研究中心联合中关村实
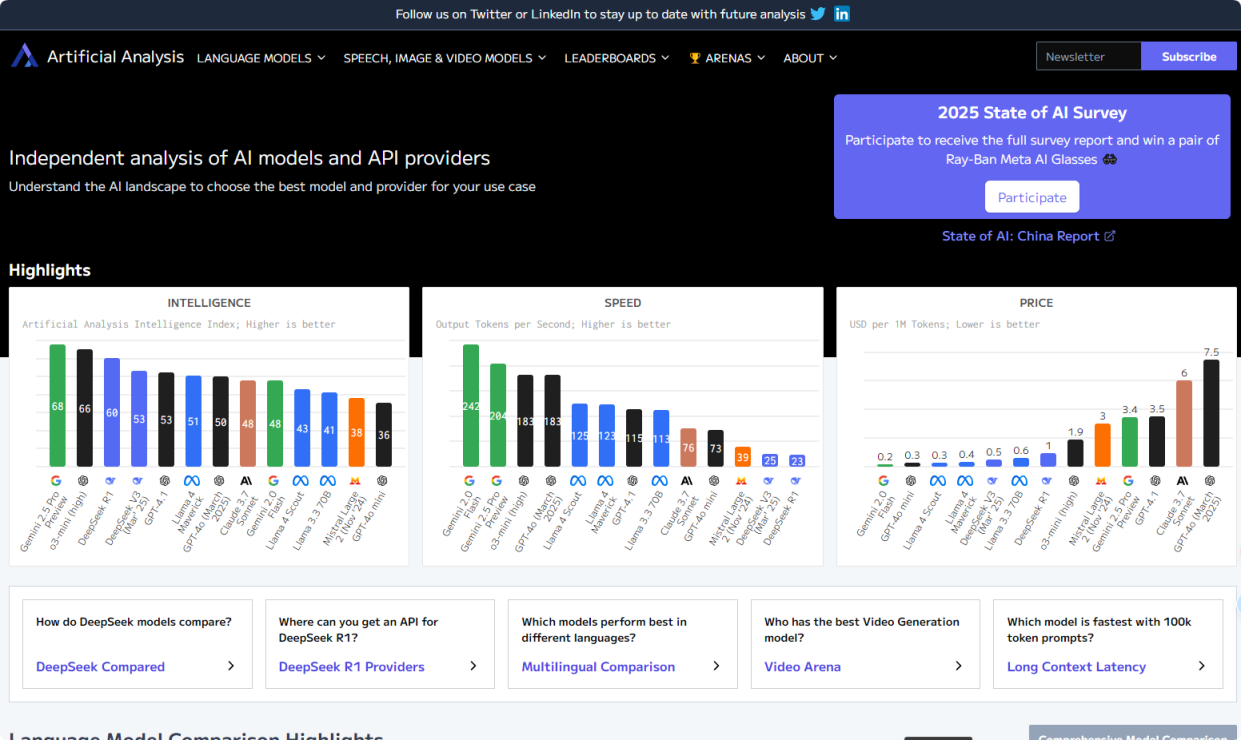
Artificial Analysis AI基准测试平台翻译站点
Artificial Analysis平台是一家领先的独立A

MMBench 提供多维度评估工具,专注于视觉-语言模型的能力验证与可靠性提升
MMBench提供多维度评估工具,专注于视觉-语言模型的能力
AI Ping
一站式大模型服务评测与模型API调用平台
lmarena.ai翻译站点
lmarena.ai 评测竞技场排行榜,是一个由加州大学伯克

Livebench LLM模型的基准测试平台翻译站点
LiveBench 是一个针对大型语言模型(LLM)的权威基

Orq.ai 是一个集成平台,帮助团队实验、部署和监控生成AI应用的全生命周期管理
Orq.ai is the #1 platform for
CLUE中文语言理解基准测评
中文语言理解测评基准,包括代表性的数据集、基准(预训练)模型
OpenCompass司南
评测榜单旨在为大语言模型和多模态模型提供全面、客观且中立的得
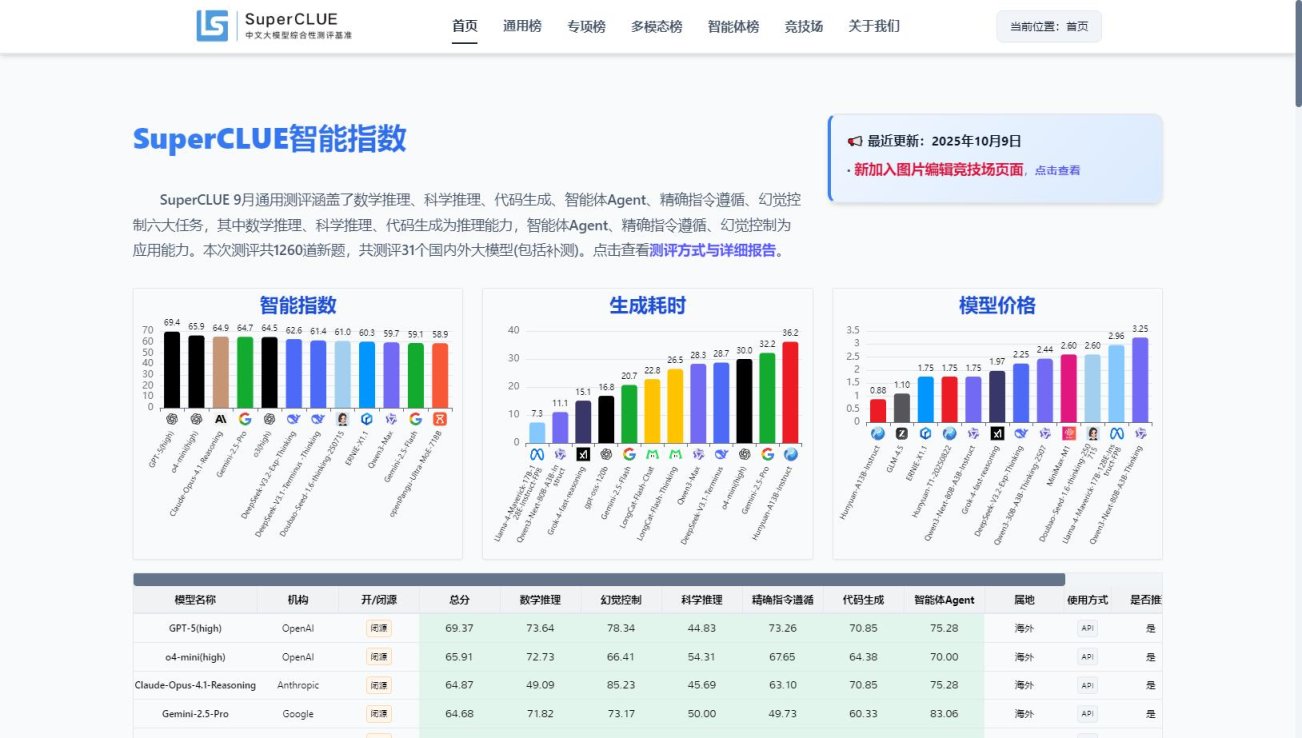
SuperCLUE
SuperCLUE是一个专注于中文大模型综合测评的权威平台,

OpenCompass司南 致力于为大模型提供全面、客观的评估参考,推动AI技术的发展与应用
评测榜单旨在为大语言模型和多模态模型提供全面、客观且中立的得

AGI-Eval 评测助力,让AI成为你更好的伙伴
AGI-Eval评测社区不仅是一个权威的AI模型能力评估平台
Open LLM Leaderboard翻译站点
Hugging Face 推出新版开源大模型排行榜(Open