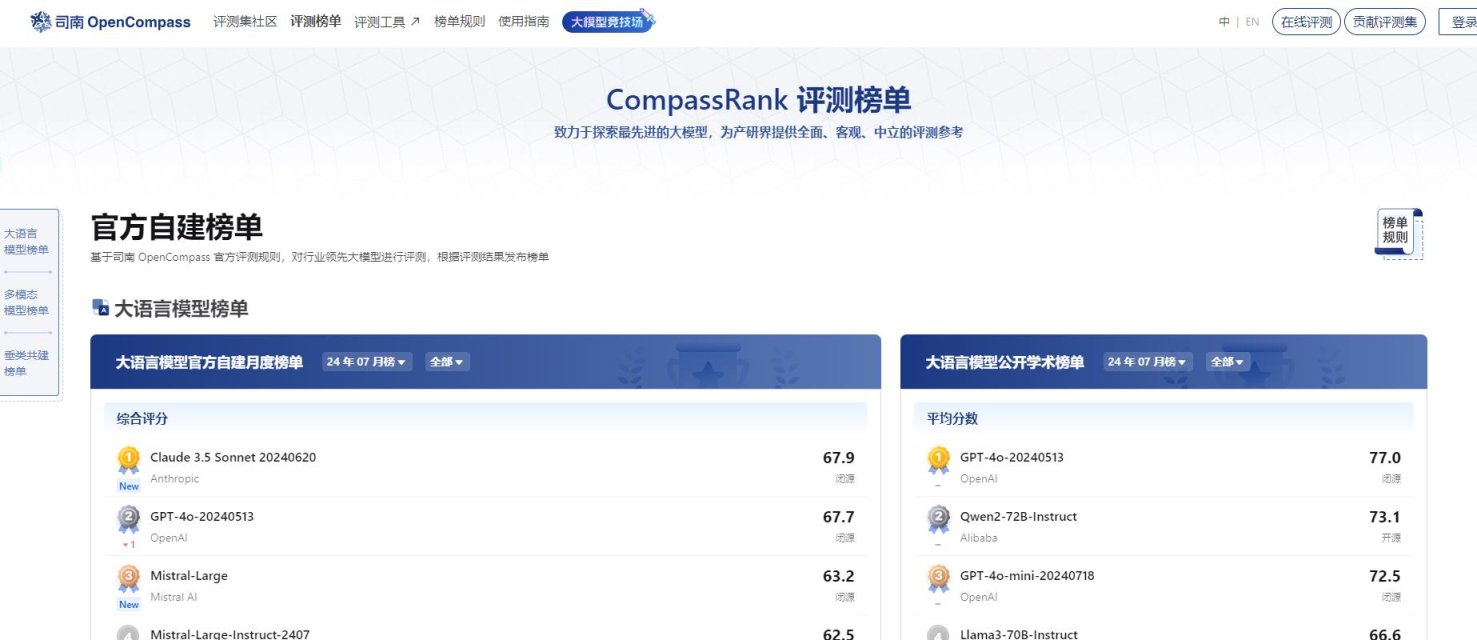
OpenCompass(司南)是由上海人工智能实验室发布的开源大模型评测体系,目前已成为业界权威的大模型评估平台,涵盖学科、语言、知识、理解、推理等评测维度,可全面评估大模型的综合能力。
以下为2024年9月截取的图片,模型排名可能随着日期不同而不同,截图仅供参考,具体以网站内为准:
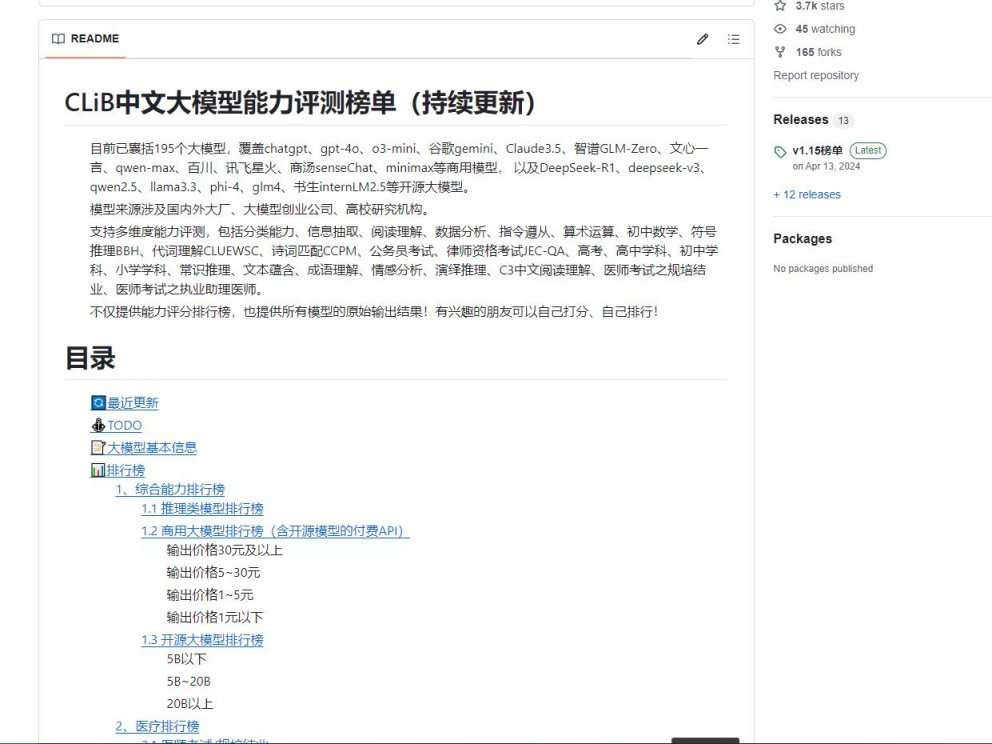
是一个关于中文大模型能力评测的榜单仓库,涵盖 195 个商用及开源大模型,进行多维度能力评测(包括医疗、教育、法律等众多领域),有多种排行榜分类且记录详细更新信
让用户出题,安排AI模型回答,由用户选择评判,从而对大模型进行评分排名和产品介绍,帮助用户筛选合适模型
FlagEval (天秤)大模型评测体系及开放平台,旨在建立科学、公正、开放的评测基准、方法、工具集,协助研究人员全方位评估基础模型及训练算法的性能,同时探索利
SuperBench是由清华大学基础模型研究中心联合中关村实验室在2024年共同发布的大模型综合能力评测榜单
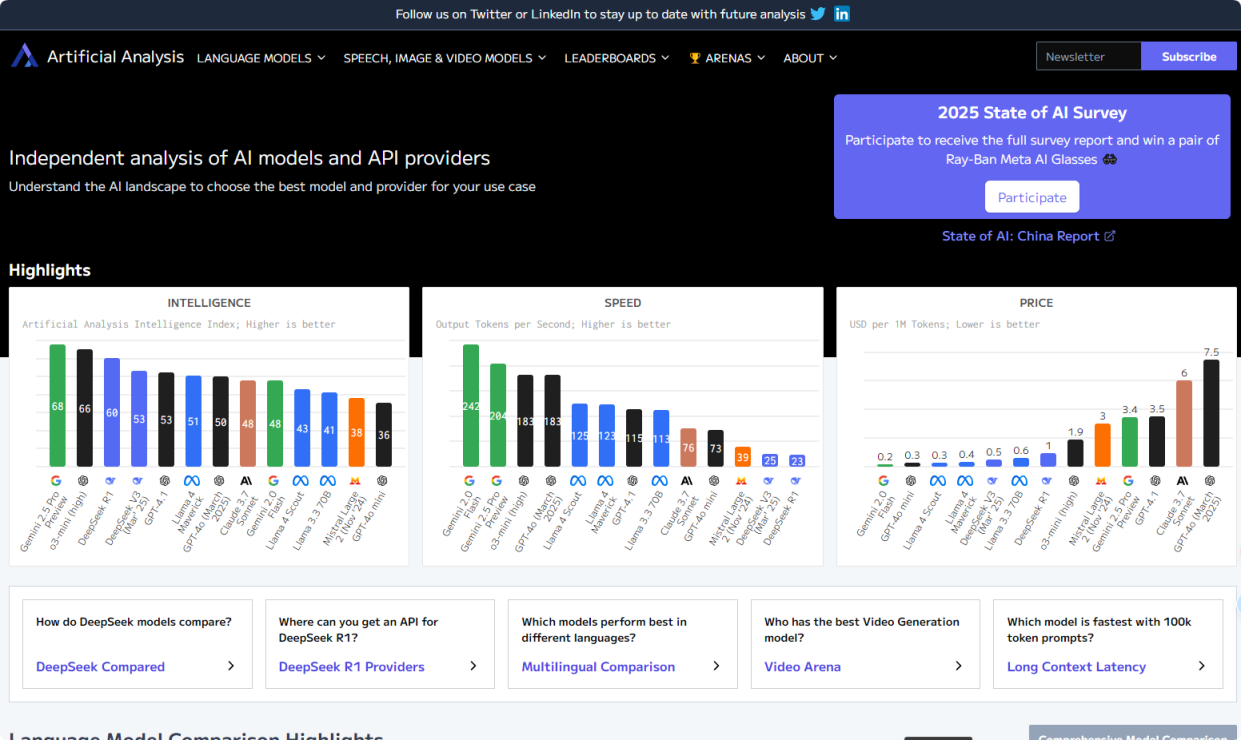
Artificial Analysis平台是一家领先的独立AI基准测试和分析平台
lmarena.ai 评测竞技场排行榜,是一个由加州大学伯克利分校 SkyLab 和 LMSYS 的研究人员开发的评测平台,用于通过人类偏好评估人工智能